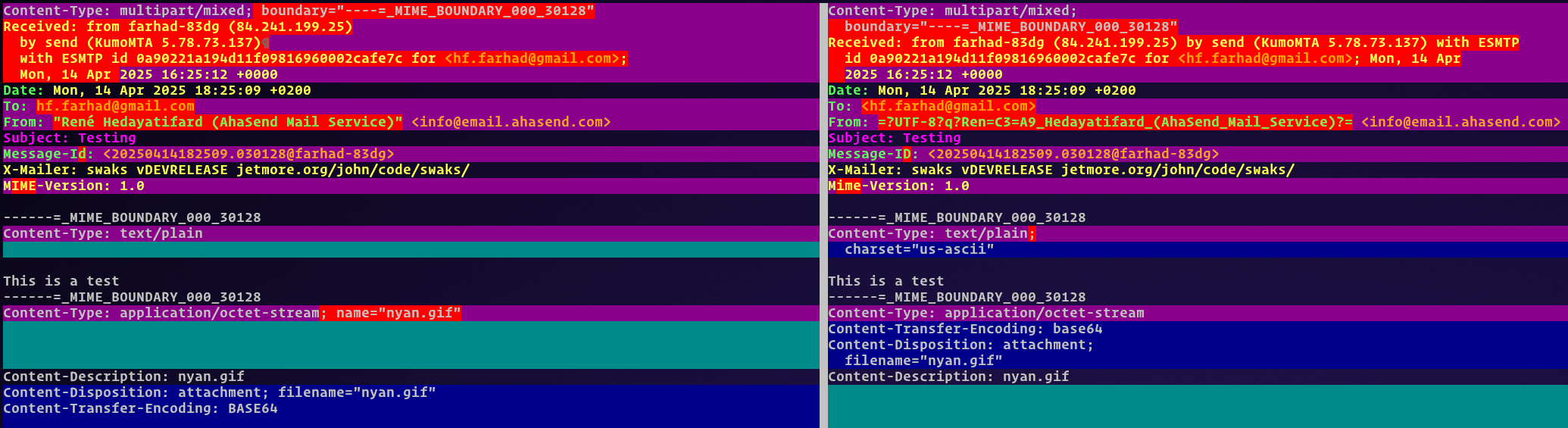
Injecting using SMTP on kumod 2025.03.19-1d3f1f67.
To reproduce, compose any message and set the From name to René Hedayatifard (AhaSend Mail Service), attach a PDF and inject using SMTP. The email will arrive, but with a blank PDF attachment.
Changing
local failed = msg:check_fix_conformance(
-- check for and reject messages with these issues:
'NON_CANONICAL_LINE_ENDINGS',
-- fix messages with these issues:
'NEEDS_TRANSFER_ENCODING|MISSING_DATE_HEADER|MISSING_MESSAGE_ID_HEADER|LINE_TOO_LONG'
)
to
local failed = msg:check_fix_conformance(
-- check for and reject messages with these issues:
'NON_CANONICAL_LINE_ENDINGS',
-- fix messages with these issues:
'NEEDS_TRANSFER_ENCODING|MISSING_DATE_HEADER|MISSING_MESSAGE_ID_HEADER'
)
in smtp_server_message_received handler fixes the issue. Seems like there’s a problem with fixing LINE_TOO_LONG that corrupts the message data.
local kumo = require 'kumo'
local function new_msg(recip)
local f <close> = io.open '/tmp/wat.txt'
local data = f:read 'a'
return kumo.make_message('sender@example.com', 'recip@example.com', data)
end
local msg = new_msg()
msg:check_fix_conformance(
'NON_CANONICAL_LINE_ENDINGS',
'NEEDS_TRANSFER_ENCODING|MISSING_DATE_HEADER|MISSING_MESSAGE_ID_HEADER|LINE_TOO_LONG'
)
print(msg:get_data())
The /tmp/wat.txt is a copy and paste of the message content I see when I use:
$ swaks --server '127.0.0.1:2025' --from info@email.ahasend.com --to hf.farhad@gmail.com --header 'Subject: Testing' --body 'This is a test' --attach-name 'sample-pdf-attachment.pdf' --h-From '"René Hedayatifard (AhaSend Mail Service)" <info@email.ahasend.com>' --attach @/home/wez/Downloads/homer.gif
The reason I ask for a sample of the input you are sending is because it removes any local variance from my test.
I don’t know if I am testing the same inputs as you are.
What I mean by not being able to reproduce this is that the output of running that script:
$ kumod --script --policy /tmp/wat.lua
is the same whether I include LINE_TOO_LONG in the flags or not.
There must be something else in your policy or input that is influencing what you are seeing
kumo.on('smtp_server_message_received', function(msg)
if msg:to_header().email == 'hf.farhad@gmail.com' then
local file = io.open('/tmp/before.eml', 'w')
file:write(msg:get_data())
file:close()
end
local failed = msg:check_fix_conformance(
-- check for and reject messages with these issues:
'NON_CANONICAL_LINE_ENDINGS',
-- fix messages with these issues:
'NEEDS_TRANSFER_ENCODING|MISSING_DATE_HEADER|MISSING_MESSAGE_ID_HEADER|LINE_TOO_LONG'
)
if failed then
kumo.reject(552, string.format('5.6.0 %s', failed))
end
if msg:to_header().email == 'hf.farhad@gmail.com' then
local file = io.open('/tmp/after.eml', 'w')
file:write(msg:get_data())
file:close()
end
-- the rest of the function
end
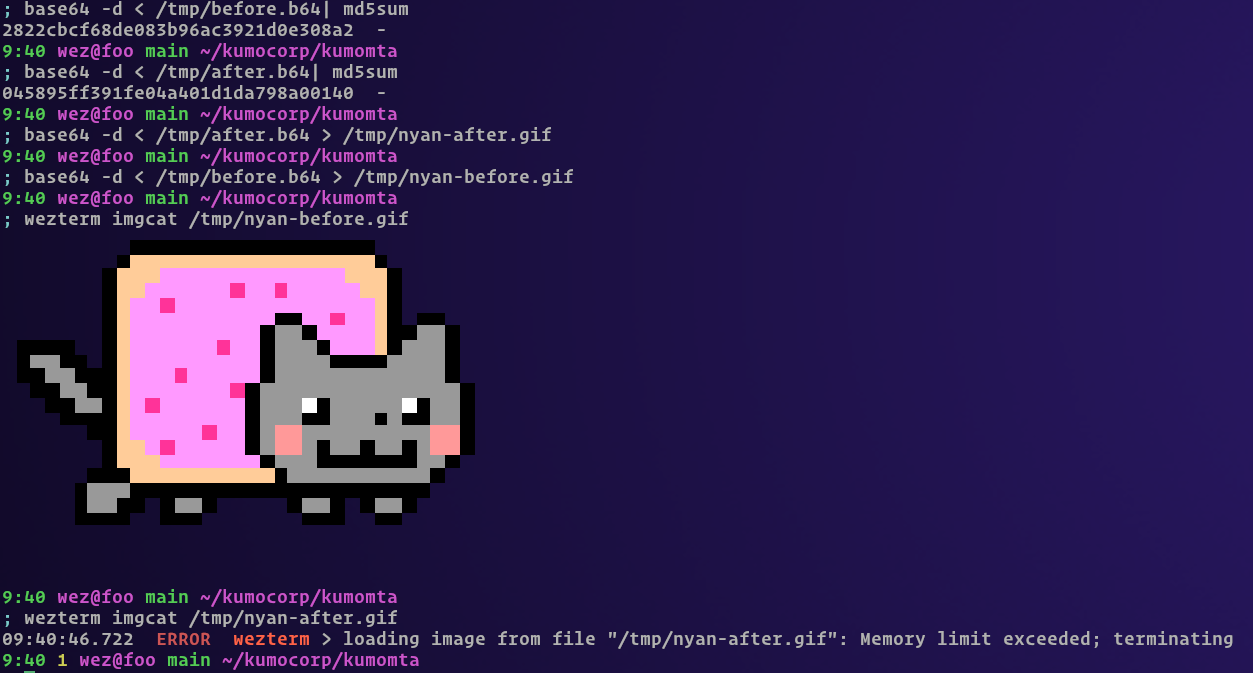
Actually, seems like I can’t reproduce the fix by removing LINE_TOO_LONG either. Not sure how I did it before! But I still think the problem is somehow related to check_fix_conformance, because the attachment base64 data has changed between before.eml and after.eml
OK, I have a fix here queued up. It’s sitting behind some TSA changes that I want to have a bit of a think about and satisfy myself that there is sufficient testing before I push; should go up later today sometime.
The gist of this issue is that we were incorrectly passing the binary attachment through the charset conversion stage during rebuild, so the bytes were being interpreted as windows-1252 text, mapped into the utf8 version of that text, and then placed into the rebuilt mime part.